内存一致性模型、内存屏障与同步
本文记录个人对于内存一致性、内存屏障和一些同步操作以及它们之间关系的理解,并列举linux内核中对应的部分实现。
参考内核版本 4.18.0-193.el8.x86_64
一些概念
缓存一致性(Cache Coherence)
缓存一致性可以看作同一地址上的多个写操作被所有CPU观测到的顺序的维护。
具备以下两个条件的系统,可以认为缓存具有一致性(具备缓存一致性的系统,可以将缓存看作是透明的)
- 任何CPU所发出的访存操作被存储器所观察到的顺序必须与CPU发出操作的顺序相同
- 每个读操作所返回的值必须是最后一次对该存储位置的写操作的值
MESI协议及其变种可以被用于实现缓存一致性。(总线嗅探、总线仲裁,使多核间事务可以串行化。在此基础上MESI协议及其变种使用状态和消息确保缓存一致性)
内存一致性(Memory Consistency)
memory consistency可以看作多个地址的访存操作被所有CPU观测到的顺序的维护。
不同内存一致性模型定义了该模型允许的读写操作的重排行为。
多拷贝原子性(Multicopy Atomicity)
需要满足两个条件:
- 多个CPU对一个地址的写操作是串行的,这些写操作被所有观察者以相同的顺序观察到,允许观察者观测不到所有的写值。
- 某个CPU对一个地址的读操作可以返回某一个写操作写入的值,只有当这个写入操作可以被所有观察者观测到时,这里的所有包含自身CPU。
由于第二个条件对CPU性能优化影响过大,一般CPU应该都不具备多拷贝原子性。
这个东西影响的主要是一个写操作对多个CPU是不是同时可见。可以理解为一个写操作需要拷贝到多个CPU,这拷贝多份的原子性。
这个东西与内存一致性是相互独立的,也就是说哪怕真的存在顺序一致性内存模型的CPU也允许非多拷贝原子性。
other multicopy atomicity
由于multicopy atomicity对于CPU性能影响过大,又有一个弱化版的概念other multicopy atomicity,也就是一个写操作对其他所有CPU同时可见。linux内核文档里将这个概念简化称呼为multicopy atomicity。linux内核中可以使用通用屏障额外确保other multicopy atomicity。
比如下面的CPU2使用的通用屏障补全了缺失的other multicopy atomicity。
1 | CPU 1 CPU 2 CPU 3 |
内存屏障是什么?
内存屏障用于在一些场景(比如同步原语)保证特定的内存访问顺序与程序顺序一致。
为什么会出现内存访问顺序与程序顺序不一致?
内存访问顺序的重排可以提供更好的性能。
为什么内存访问顺序重排可以提供更好的性能?
现代CPU指令执行速度比内存访问速度快几个数量级,为了提升访存速度为CPU增加了比内存更快的缓存,为了使每个CPU的写操作不会影响所有CPU缓存数据一致而使用缓存一致性协议(比如MESI协议),这使所有CPU的缓存数据看起来与内存是一体的,或者说是透明的。
但是这种情况下有些无条件的写操作还需要等待其他CPU响应以获取缓存行的E状态,这种等待时间是没有价值的。解决这种问题的方式可以是引入新的层,同时将对缓存的操作异步化,使普通的读写指令不需要做非必要的等待。异步操作的代价就是不同地址的数据修改操作被各个CPU观测到的顺序不完全相同。
内存访问重排是如何做到的?
假设有这样一个架构,多核CPU,每个CPU和内存中间有缓存(cache)。
总线嗅探、总线仲裁,使得多核间可以事务串行化。在此基础上MESI协议使用状态和消息确保缓存的数据一致,操作缓存数据也是同步操作,此状态下缓存数据和内存数据可以看作是一体的,CPU对缓存的修改可以被其他CPU同步观测到,缓存可以看作是透明的。
这时CPU对本地有效的缓存行的读性能很好。
但是,写缓存还是同步操作,当缓存行不是E或M状态时需要先与其他CPU交互通信才能执行写操作。
为了提升写操作性能,增加写缓冲区(store buffer)。写指令放入到写缓冲区同时向其他CPU发出RFO请求(Request For Ownership),不等待ack就直接返回继续执行后续指令。ack消息返回后再写进缓存。读取数据时也会在写缓冲区中搜索。
写缓冲区会导致什么?
会导致写乱序。需要等待RFO ACK的写操作延迟生效到内存,后执行的对已经处于排他状态内存地址的写操作不需要RFO可能先生效到内存,就是StoreStore重排。后执行的读操作同理。这就StoreLoad重排。
如果强制写操作必须都进入Store Buffer做FIFO排队,就能避免StoreStore重排。
1 | x和y初始均为0 |
1 | x和y初始均为0 |
写缓冲区容量有限,等待ack的操作填满写缓冲区后,写操作依然要等待。
继续增加失效队列(invalidation queue),接收方收到RFO请求后将消息放入失效队列并直接响应ack。失效队列中的消息排队等待CPU处理。失效队列中的消息并不会被CPU读取数据时观测到。
失效队列会导致什么?
会导致读乱序。本地已经缓存的数据旧值时间延长,先执行的读取未缓存数据的指令可能读到更新的值。(可以看到这个效果甚至不满足PSO部分存储定序模型,也就是说X86中均不会有此种效果的实现)
写缓冲区和失效队列,导致多个CPU对多个内存地址的读写预期顺序不再一致,或者说看起来表现为指令重排序。
当然CPU实际上要复杂得多,这里的描述只是一个更有利于直观理解的假设的架构,实际软件开发中是不应该依赖这种简单不准确的描述。
操作系统开发人员应该关注的是每种CPU允许的重排类型,提供合适的内存屏障、原子操作及其他类型同步工具api的封装。
驱动开发人员应该关注于正确理解这些工具api的语义,并正确使用这些封装后的api(假定运行的CPU均为Alpha架构)。
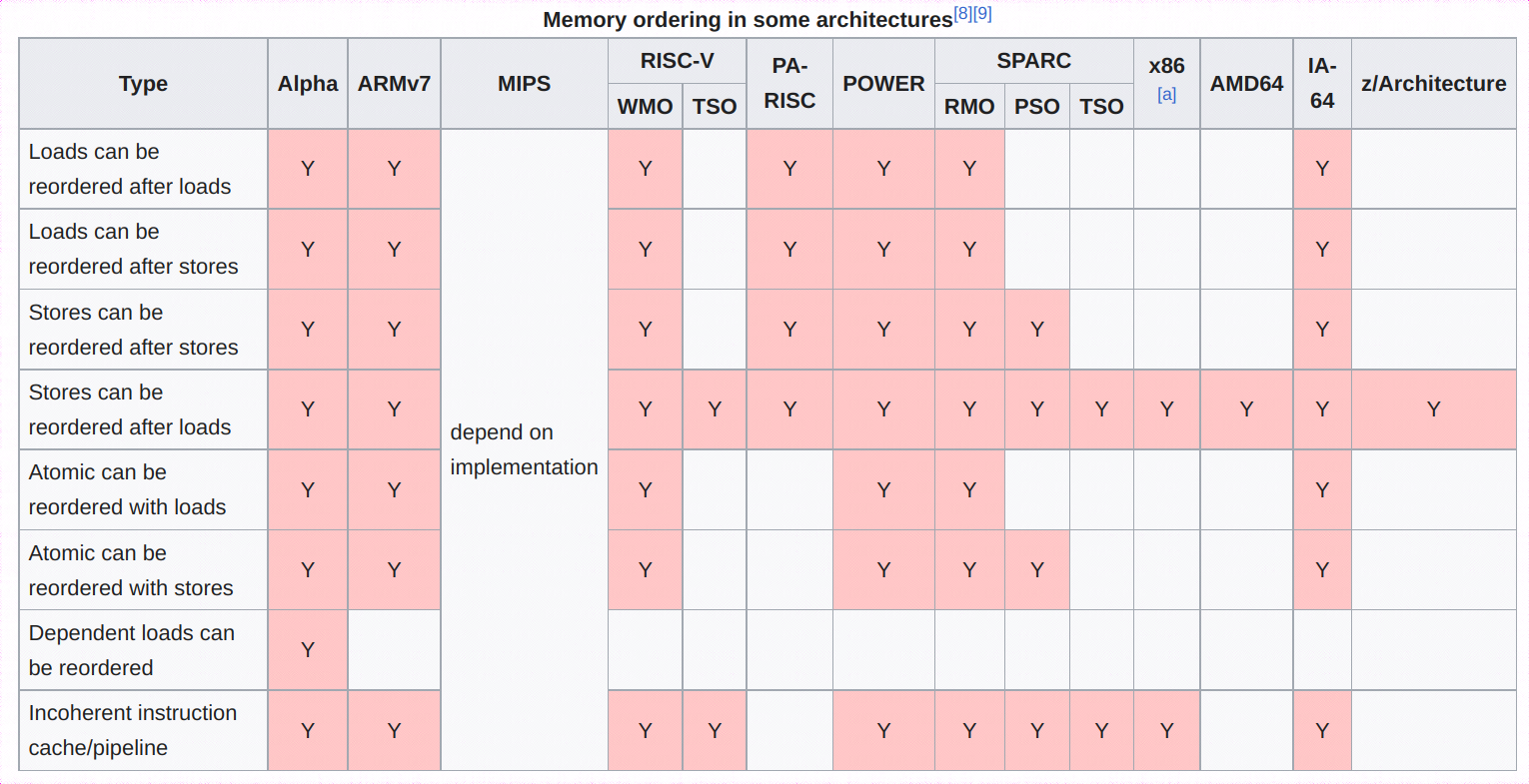
都有哪些内存访问重排类型?
参考下图。其中Incoherent instruction cache/pipeline,个人理解应该是指令和数据使用不同的缓存,因此self-modifying code修改指令内存后需要特定的指令刷新指令缓存。
都有哪些内存一致性模型?
不同架构CPU因为硬件设计不同,允许的重排类型不同。内存一致性模型定义了该模型下允许的重排类型,几个典型的内存一致性模型如下:
- 顺序一致性(Sequential Consistency)模型。完全不允许重排。
- 完全存储定序(Total Store Order)模型。允许对StoreLoad重排。(可以简单理解为增加了Store Buffer,且限制写操作必须经Store Buffer做FIFO。X86使用该模型)
- 部分存储定序(Part Store Order)模型。允许对StoreLoad和StoreStore重排。(可以简单理解为增加了Store Buffer,未做FIFO限制)
- 宽松存储定序(Relax Memory Order)模型。允许任意无依赖关系的指令重排。(ARM64使用该模型)
Alpha处理器允许有依赖关系的读操作重排,不属于上面4个模型。
从可移植性考虑开发中不应该依赖具体的模型,而应该规范使用内存屏障(也就是假定均为Alpha架构)。
编译屏障
volatile
阻止编译器对变量做任何优化。
在内核模块开发中这个关键字是不应该存在的,如果使用了该关键字,需要十分仔细确认是否达成了特定的目标。这个关键字可以用于内存映射的IO寄存器,但是此种情况一般使用封装过的函数进行访问。在内核模块开发中对于并发访问的场景,不应该期望该关键字提供有效的保护措施,而应该正确使用编译屏障、内存屏障、锁、rcu等其他手段。
barrier
阻止编译器对barrier前后代码重排,强制编译器在循环中每次重新读取条件变量。
READ_ONCE / WRITE_ONCE
可以看作barrier的弱化,只对使用该api的访存操作生效。(循环条件中的优化种类很多)
普通单指令不能完成的非地址对齐的访存操作,可以用READ_ONCE/WRITE_ONCE单步完成。
编译器可以移动READ_ONCE/WRITE_ONCE保护的操作跨越不包含READ_ONCE/WRITE_ONCE/barrier的代码。
并行共享的变量,就都不要用普通读写操作就对了。(volatile修饰的变量不需要,这玩意同样阻止编译器对变量的优化)
内存屏障 memory barrier
linux提供抽象的内存屏障函数,可以阻止访存重排和cpu指令执行重排,同时也包含了barrier编译屏障的功能(地址依赖屏障不包含编译屏障,编译器会根据该依赖关系不会做重排)。
linux有7个基本类型内存屏障函数。强制内存屏障用于MMIO场景(即使是单核),普通SMP并行场景不需要使用强制内存屏障。
1 | TYPE 强制内存屏障 SMP内存屏障 |
- 写屏障(smp_wmb),在内存的视角看屏障前后的写操作都无法跨越屏障。但是不保证屏障前的写操作都对内存立即可见。
- 读屏障(smp_rmb),在内存的视角看屏障前后的读操作都无法跨越屏障。但是不保证屏障后的读操作一定读到内存当前状态。
- 通用屏障(smp_mb),不只是写屏障与读屏障的和。在内存视角看屏障前后的读写操作都无法跨越屏障,通用屏障还保证了other multicopy atomicity。但是不保证屏障指令执行时本地缓存与内存同步。
- 地址依赖屏障(smp_read_barrier_depends),对应场景是先读一个地址,再读该地址存储的数据。目前看只针对Alpha架构允许的有依赖关系的读操作重排,非常反直觉,其他任何架构都不允许此种排重。4.18内核的READ_ONCE内包含了该屏障,rcu_dereference使用了READ_ONCE。内核一些难以理解的操作与这个地址依赖屏障有关。
还有一些相对不常用的。
- smp_store_mb
- smp_mb__before_atomic
- smp_mb__after_atomic
- dma_wmb
- dma_rmb
- dma_mb
- pmem_wmb
- io_stop_wc
linux内核中各种锁操作也包含隐式内存屏障,比如自旋锁、读写自旋锁、mutex、信号量、读写信号量等,均包含ACQUIRE / RELEASE语义
ACQUIRE
这类似一个单向渗透屏障。ACQUIRE之后的访存操作一定生效在ACQUIRE之后,之前的访存操作可以生效在ACQUIRE之后。一个ACQUIRE操作一定在后运行的ACQUIRE或RELEASE之前完成。
包括锁操作和smp_load_acquire、smp_cond_load_acquireRELEASE
这类似一个单向渗透屏障。RELEASE之前的访存操作一定生效在RELEASE之前,之后的访存操作可以生效在RELEASE之前。
包括解锁操作和smp_store_release
ACQUIRE / RELEASE重点是单向渗透,临界区外的指令可能在临界区中执行,ACQUIRE+RELEASE一起使用不等于一个通用屏障。
锁原语的临界区用于保护数据,需要并行访问数据的所有位置配套使用锁原语临界区。
linux调度器包含通用内存屏障,保证了一个task在调度到另一个CPU运行前,在之前CPU的所有内存操作均对新CPU可以见。
内存屏障不能保证什么?
- 内存屏障前的任何访存操作不能保证在内存屏障指令完成时生效到内存。内存屏障只可以限制该CPU上访存操作生效的部分相对顺序。
- 一个CPU上的内存屏障不会对其他CPU和设备的访存操作产生直接影响,其他CPU只有使用配对合适的内存屏障才能保证观测到第一个CPU上访存操作的正确顺序。
- 无法保证与CPU交互的其他硬件设备不会做访存重排。
同步操作
内存屏障仅保证内存访问操作顺序性,不保证多核间的同步,因此还需要其他同步机制
原子操作
linux内核提供了原子类型及对应的原子操作api,可以分为RMW(read、modify、write)及非RMW两类。
- 非RMW操作比较简单,比如atomic_read、atomic_set,不涉及同步。
- RMW操作,比如atomic_add、atomic_xchg之类,这类api保证了原子操作,这必然需要多CPU同步,其实现依赖各架构提供的不同指令。
以x86下atomic_add为例,可以看到其依赖lock指令实现同步。
lock修饰的指令操作的内存只能由当前CPU使用。附带有通用屏障效果。
这个实现可以是锁总线也可以是通过缓存一致性协议锁定缓存行(比如先通过MESI协议获取并保持缓存行的E或M状态再进行独占的RMW操作,直到RMW操作完成才允许释放M状态)。
LOCK_PREFIX宏的作用是将所有lock指令地址保存在.smp_locks段。smp编译的内核运行在单核环境时,可以将lock指令替换成nop以降低性能损耗,cpu hotplug时又可以恢复lock。
1 | /* |
锁操作
原子操作也是各种锁实现的基础,以spin_lock为例,其实现代码中可以看到依赖的是原子操作以及内存屏障。
其中pv_lock_ops.queued_spin_lock_slowpath可能的函数符号
- esxi虚拟机下为
native_queued_spin_lock_slowpath - 在kvm虚拟机下为
__pv_queued_spin_lock_slowpath
这两个函数的实现均是kernel/locking/qspinlock.c中的queued_spin_lock_slowpath,该文件前部分先通过宏替换定义出函数native_queued_spin_lock_slowpath,最后再通过更改部分宏定义并include自身文件的方式再次使用同样的代码定义出函数__pv_queued_spin_lock_slowpath,区别在于两个函数内pv_enabled()及一些其他宏的值不同。
1 | static __always_inline void pv_queued_spin_lock_slowpath(struct qspinlock *lock, |
其他
为什么一些环境中printk能起到内存屏障一样的影响?
printk内部实现中调用了raw_spin_lock和raw_spin_unlock,以x86架构为例内部包含lock指令,具备通用屏障效果,但这种x86架构下raw_spin_lock提供内存屏障的能力是依赖具体实现的,本身并不在spinlock自身语义中,因此是不可以依赖的,需要内存屏障的场景还是应该使用内存屏障命令。printk的该副作用也会影响一些场景的bug复现及调试。
精确中断:
中断前的指令都执行完成,中断后的指令都没有执行。确保中断发生时刻正在运行的代码不被CPU乱序和内存一致性问题影响,可以看到一个顺序一致的内存状态。
cpu_relax:
用于忙等待,在cpu支持情况下,具备内存屏障、降低功耗和让位同核超线程能力。x86下为rep;nop,其编译结果应该与pause等价(f390)。
参考
Linux 内核文档 memory barriers
Memory Barriers: a Hardware View for Software Hackers
A Primer on Memory Consistency and Cache Coherence