RCU(Read, Copy, Update)是一组Linux内核API,实现了一种同步机制,允许多个读者与写者并发操作而不需要任何锁,这种同步机制可以用于保护通过指针进行访问的数据。RCU读者只有很低的额外成本,在典型服务器内核配置下甚至是0成本。如果可能有多个写者,写者之间需要使用其他同步机制。除了使用RCU API直接访问指针数据,更多的使用方式是封装RCU API使其用于链表访问。
RCU适用于读取量很大、而且可以接受读取到旧数据的场景。一个典型场景就是内核路由表,路由表的更新是由外部触发的,外部环境的延迟远比内核更新延迟高,在内核更新路由表前实际已经向旧路径转发了很多数据包,RCU读者按照旧路径再多转发几个数据包是完全可以接受的,而且由于RCU的无锁特性,实际上相比有锁的同步机制,内核可以更早生效新的路由表。路由表这个场景,以系统内部短时间的不一致为代价,降低了系统内部与外部世界的不一致时间,同时降低了读者成本。
抢占式RCU和更多使用方面内容更新在这里
Q: 为什么只能保护通过指针访问的数据?
Q: 读者0额外成本是怎么做到的?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static inline void rcu_read_lock (void ) __rcu_read_lock(); __acquire(RCU); rcu_lock_acquire(&rcu_lock_map); rcu_lockdep_assert(rcu_is_watching(), "rcu_read_lock() used illegally while idle" ); } static inline void __rcu_read_lock(void ){ preempt_disable(); } #define preempt_disable() barrier() #define barrier() __asm__ __volatile__("" : : :"memory" )
Q: 读者额外成本很低,那么写者呢?
本文内容参考内核版本 3.10.0-862.el7.x86_64
RCU 原理 RCU是基于保护通过指针访问的数据而达成并发安全的同步机制,这就涉及两个场景,插入和读取并发、删除和读取并发(更新操作可以理解为这两个场景的结合)。
插入读取并发 设想有一个初始化为NULL的全局变量指针gp被更新为指向一个新分配内存并初始化的数据结构(假设并发写操作已有合适的锁保护):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 struct foo { int a; int b; int c; }; struct foo *gp = NULL ;p = kmalloc(sizeof (*p), GFP_KERNEL); p->a = 1 ; p->b = 2 ; p->c = 3 ; gp = p;
然后这段代码并不会阻止编译器和CPU对最后四行代码的执行顺序做保证。如果对gp的赋值操作在数据结构初始化之前被执行,那么读者将会访问到未经正确初始化的数据。因此需要添加内存屏障和编译器指令以保证gp的赋值一定要在数据结构初始化之后,但是内存屏障的正确使用并不容易。rcu_assign_pointer原语通过将内存屏障和编译器指令包装于其中,强制编译器和CPU保证对gp的赋值在对p成员赋值后。
然而只对写操作顺序做保证并不够,同样要注意读者操作的顺序性。
1 2 3 4 p = gp; if (p != NULL ) { do_something_with(p->a, p->b, p->c); }
这段读操作代码看起来是没有问题的,但不幸的是,在Alpha架构CPU以及编译器启用值预测优化时,p->a、p->b、p->b的取值可能会在p前,因此我们需要阻止编译器和CPU进行这种侵略性过高的行为,以使并发读取可以得到正确的结果。rcu_dereference原语同样包装了内存屏障和编译器指令,强制保证读操作的合理顺序。
1 2 3 4 5 6 rcu_read_lock(); p = rcu_dereference(gp); if (p != NULL ) { do_something_with(p->a, p->b, p->c); } rcu_read_unlock();
rcu_dereference原语和rcu_assign_pointer原语结合使用,保证了通过指针访问到的数据一定经过了合理的初始化。代码中的rcu_read_lock和rcu_read_unlock原语同样是不可或缺的,它们共同定义了RCU读临界区,具体含义见下节,与其他锁机制不同,这个临界区并不会引起任何等待或调度,也不会阻止写操作的并发执行,在非抢占内核下这两个原语实际上并不生成任何代码。
删除读取并发 删除操作(包括更新)与插入不同的是,还要面对旧数据结构回收的问题,写者必须要等待可能持有旧数据结构的读者不再读取旧数据结构后才可以执行回收操作,在RCU中这个等待的读者操作区间叫做RCU读者临界区,一个读者调用的rcu_read_lock和rcu_read_unlock原语分别标识了临界区的开始和结束,临界区可以嵌套,可以包含任意多的代码,但是不能够显式的阻塞和睡眠(也就是不能触发调度)。
RCU等待相关的临界区退出,但并不直接判断临界区何时退出,实现细节见下文的RCU实现 。
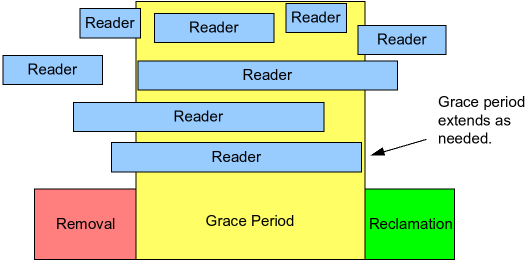
参考下图,RCU以一种称为宽限期(Grace Period)的方式等待已经存在的临界区运行结束。需要注意的是,grace period开始之后才开始的临界区并不会影响grace period的结束时间。
下面展示一种基础的RCU等待读者操作完成的算法:
做修改操作,比如修改全局变量指针的指向。
等待之前所有的RCU临界区执行完成(比如使用synchronize_rcu原语)。
做回收,比如释放全局变量指针之前指向的结构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 struct foo { int a; int b; int c; }; struct foo *gp = NULL ;p = rcu_dereference(gp); if (p == NULL ) { } q = kmalloc(sizeof (*q), GFP_KERNEL); *q = *p; q->b = 2 ; q->c = 3 ; rcu_assign_pointer(gp, q); synchronize_rcu(); kfree(p);
上面代码段的21、22、23行实现了前文所说的三个步骤。18-21行展示了RCU(read copy update)的名字含义:在允许读者并发read的同时,18行copy,19-21行update。
synchronize_rcu原语暂时还比较难理解,但只要知道它等待所有之前存在的临界区执行完成,之后不会有任何读者能够访问到旧的指针指向的数据,也就可以安全的回收旧数据了。
为了更便于理解,这里有一个trick,Classic RCU临界区中不允许阻塞和睡眠,因为当一个CPU经历一次调度后,我们认为之前的RCU临界区一定运行完成了,这就意味着当所有CPU都至少经历一次调度后,之前所有的RCU临界区都执行完成了,也就意味着synchronize_rcu可以安全的返回了。
因此Classic RCU的synchronize_rcu可以从概念上简单理解为:
1 2 for_each_online_cpu(cpu) run_on(cpu);
这里的run_on切换当前线程到指定的CPU上,也就强制指定CPU做了一次调度。for_each_online_cpu对所有CPU做了轮询,这就保证了所有RCU临界区执行完成。虽然这种方式在不允许RCU临界区抢占的内核下可以工作,但在配置了CONFIG_PREEMPT_RT(一般服务器并不采用该种配置)的内核中使用的realtime RCU使用的是另一种方法来判断临界区的结束。当然,实际上内核RCU的实现远比这个复杂。
RCU API 前面已经看到了一些RCU API,这里简单汇总一些,更多API参考头文件include/linux/rcupdate.h。
读者临界区rcu_read_lockrcu_read_lock
RCU指针取值rcu_dereference
RCU指针修改rcu_assign_pointer
同步等待grace periodsynchronize_rcu
注册回调函数,异步等待grace periodcall_rcu
异步等待grace period后释放内存kfree_rcu
另外有一组API后缀_bh,不同之处在于将中断下半部的运行结束也看作临界区完成的标识,因此可以猜到对应的临界区原语rcu_read_lock_bh内部封装了关闭中断下半部。
RCU 链表 实际使用中,RCU更多的用于链表操作,因此有一组包装了RCU的链表API。Linux内核中有两种双向链表,一种是环形链表结构struct list_head,一种是线性链表结构struct hlist_head/struct hlist_node(用于哈希表,节省哈希表表头的内存占用)。为了简单起见,这里的图不展示双向结构,只展示单向next指针。RCU链表操作也只允许读者单向遍历,因此只展示单向链接并不影响理解。
链表删除 以下代码作为RCU链表删除的例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct foo { struct list_head list ; int a; int b; int c; }; LIST_HEAD(head); p = search(head, key); if (p != NULL ) { list_del_rcu(&p->list ); synchronize_rcu(); kfree(p); }
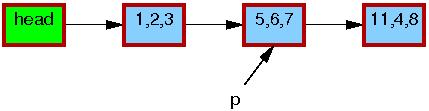
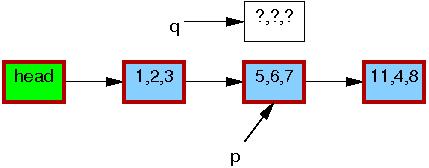
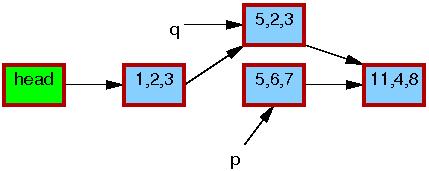
假设包含指针p的链表初始状态如下:
每个元素中的三个成员分别代表a、b、c的值。每个元素的红色边框表示可能有读者持有它们的引用,由于读者并没有与写者直接同步,因此读者可能会与修改操作并发执行。
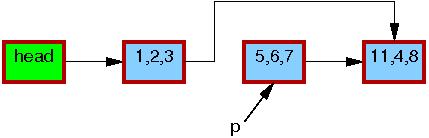
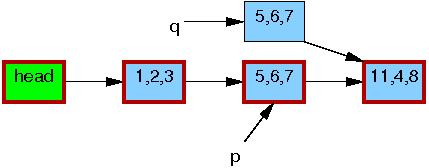
第13行的list_del_rcu运行结束后,如下图所示,元素5,6,7被从链表中移除。因为读者并没有与写者做直接同步,仍可能有读者正在遍历该链表。这些读者可能看到刚刚移除的元素,也可能看不到,这取决于读者遍历和写者修改的时机。那些看到了旧版本链表的读者可能在元素被从链表移除后仍然访问该元素。这时元素5,6,7的边框仍是红色的,此时在不同的读者看来链表存在两个版本。
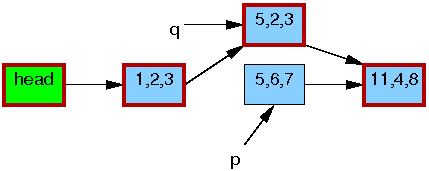
这里需要注意的是,读者在离开临界区后,绝对不允许再持有链表任何元素的引用(也就是不允许再访问链表的任何元素)。因为一旦14行的synchronize_rcu执行完毕,意味着所有之前的读者都已经离开了临界区,没有任何读者可能持有刚刚移除的元素p,可以看到它由黑框标识,此时所有的读者看到的链表又回归为唯一的版本。
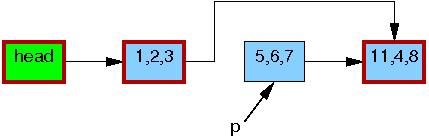
这时p指向的元素5,6,7可以被安全的释放了。
链表修改 以下代码作为RCU链表修改的例子。
1 2 3 4 5 6 7 q = kmalloc(sizeof (*p), GFP_KERNEL); *q = *p; q->b = 2 ; q->c = 3 ; list_replace_rcu(&p->list , &q->list ); synchronize_rcu(); kfree(p);
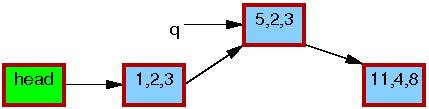
假设包含指针p的链表初始状态如下:
第一行kmalloc分配了一个待替换的元素。
第二行将旧元素内容复制给新元素。
第三行将新元素成员b的值更新为2。
第四行将新元素成员c的值更新为3。
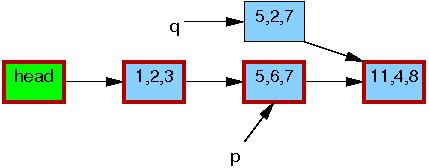
到第五行,做了替换操作,这时新的元素可以被读者看到了。如下图所示,此时链表存在两个版本,之前的读者可能看到元素5,6,7,新的读者看到的将是元素5,2,3,但是任何读者看到的都是一个可以顺利遍历的合理的链表。
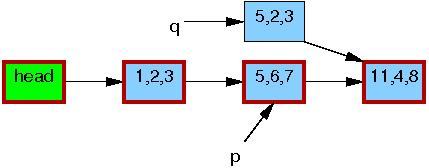
第六行synchronize_rcu执行后,会经历一个grace period,之后所有的在list_replace_rcu之前进入临界区的读者都已经完成读操作离开了临界区,并且不会有新的读者访问到元素5,6,7。这时链表回归到唯一版本。
第七行kfree执行后,链表如下所示。
尽管RCU的命名来源是替换场景,但是Linux内核中大多数RCU操作都是前文所示的链表删除 。
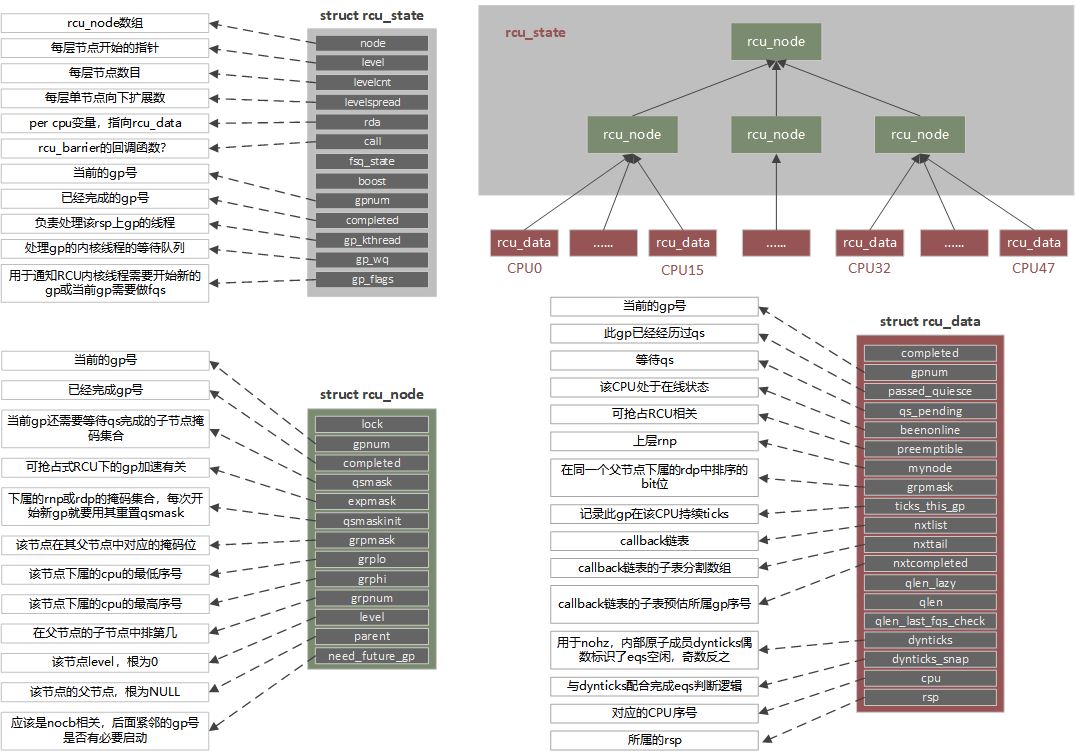
RCU 实现 在不同的编译配置下有不同的RCU实现,比如经典RCU、可抢占RCU、可睡眠RCU,这里只记录经典RCU的实现(也是典型服务器配置下使用的RCU)。经典RCU的实现又分为rcu tiny和rcu tree,tiny版只适用于UP单核系统,树形RCU适用于SMP多核系统,这里记录树形RCU实现。
下面可能直接使用简称,rsp(rcu_state pointer),rnp(rcu_node pointer),(rcu_data pointer)。
概念
quiescent states(qs)
extended quiescent state(eqs)
CONFIG_HZ_PERIODIC
CONFIG_NO_HZ_IDLE
CONFIG_NO_HZ_FULL
CONFIG_NO_HZ_FULL_ALL
rcu boostCONFIG_RCU_BOOST,与可抢占RCU配合使用,用于避免低优先级进程长期无法退出临界区而造成内存耗尽。典型配置下为关闭状态。
nocb
CONFIG_RCU_NOCB_CPU_NONE
CONFIG_RCU_NOCB_CPU_ZERO
CONFIG_RCU_NOCB_CPU_ALL
大体流程 这里先描述一下一个RCU的大体工作流程,有一个直观认识。
call_rcu将rcu_head挂载到当前CPU的rdp成员nxtlist末尾。CPU的本地定时器中断isp中通过rcu_pending判定需要软中断工作,激活软中断。
软中断通过cpu_needs_another_gp判定需要开始一个新的gp,调用rcu_start_gp将rsp->gp_flags标记为RCU_GP_FLAG_INIT。
RCU内核线程观察到RCU_GP_FLAG_INIT,调用rcu_gp_init,为rsp->gpnum设定新的gp序号,然后遍历所有rnp重置qsmask并更新gpnum。(顺便会将当前CPU的rdp状态也更新一下,包括gp序号和重置qs)
每个其他CPU在本地定时器中断isp中经过rcu_pending发现rdp的gpnum不等于rnp的gpnum,有新gp需要处理,因此激活软中断。
每个其他CPU在软中断中将gpnum从rnp向下传递到rdp,并重置qs相关状态(这个与4中最后的额外工作一起将所有CPU的rdp更新到新gp状态)。
每个CPU在本地定时器中断isp中判定是否符合qs条件,如果符合则更新rdp中passed_quiesce为1,表示经历过qs。经过rcu_pending判定需要软中断工作,激活软中断。
每个CPU在软中断中将qs完成状态逐级向上汇报更新rnp的qsmask。
最后一个更新会将根节点rnp的qsmask置为0,这时唤醒RCU内核线程。
RCU内核线程发现根节点rnp的qsmask已经为0,调用rcu_gp_cleanup,遍历更新所有rnp的comleted为rsp的gpnum,并更新rsp的completed。(顺便推进当前CPU的rdp的callback链表,将完成的callback置于合适的子链表中)
每个CPU在本地定时器中断中经过rcu_pending发现rdp的completed不等于rnp的completed,有已经完成的gp需要处理,因此激活软中断。
每个CPU在软中断中通过rcu_process_gp_end将completed从rnp向下传递到rdp,并将已经完成gp的callback放入nxtlist合适子链表中。最后通过rcu_do_batch完成callback的回调执行。
每次只有一个gp在运行中,运行的gp序号gpnum从rsp向下传递到rnp和rdp,qs状态从rdp向上汇报到rnp和rsp,完成的gp序号completed从rsp向下传递到rnp和rdp,最后再执行回调callback。
call_rcu主要就是将rcu_head挂载到合适的rdp就可以了。只有当堆积过多时才会采取一些可以推动gp的操作。CPU本地定时器中断主要就是判定当前是否处于qs(如果处于qs则设定passed_quiesce),然后根据rcu_pending决定是否激活软中断。
软中断中完成的操作多一些,包括:
推进callback多个子链表。
将completed从rnp向下传递到rdp。
将gpnum从rnp向下传递到rdp。
向上汇报qs。
合适的情况下设定RCU_GP_FLAG_INIT。
执行完成gp的callback。
内核线程部分大体上就是一个无限循环:
等待RCU_GP_FLAG_INIT,rsp开始一个新gp,将新gpnum向下传递给rnp。
等待根节点rnp的qsmask为0(既为所有参与CPU都经历过qs)。
更新completed为刚刚的gpnum,然后将completed向下传递给rnp。
合适的情况下设定RCU_GP_FLAG_INIT。
数据结构 回调链表 rcu_head的结构比较简单,只有一个回调函数的指针和一个单向链表。
1 2 3 4 5 6 7 8 9 10 struct callback_head { struct callback_head *next ; void (*func)(struct callback_head *head); }; #define rcu_head callback_head
rcu_head会挂在到rcu_data成员nxtlist上,这个链表被分割为4个部分,这4个部分由nxttail这个数组的4个成员来分割如下:
[nxtlist, *nxttail[RCU_DONE_TAIL])[*nxttail[RCU_DONE_TAIL], *nxttail[RCU_WAIT_TAIL])[*nxttail[RCU_WAIT_TAIL], *nxttail[RCU_NEXT_READY_TAIL])[*nxttail[RCU_NEXT_READY_TAIL], *nxttail[RCU_NEXT_TAIL])
这里*nxttail[RCU_NEXT_TAIL]永远都是NULL,因为这是链表末尾。
树形结构
初始化 RCU所需要的初始化操作在多个位置:
rcu_init初始化了RCU所需要的全局数据结构(也是树形几何结构),位于start_kernel -> rcu_init。rcu_init_nohz初始化nocb的简单标识,位于start_kernel -> rcu_init_nohz,在rcu_init后。rcu_spawn_gp_kthread为每个rsp创建了内核线程处理grace period的开始和结束,也创建了负责boost和nocb的线程(这部分与rcu_init有重复)。
rcu_init 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 +--------+ |rcu_init| +---+----+ | | +-------------------+ +---+rcu_bootup_announce| | |打印RCU相关启动信息| | +-------------------+ | | +------------------------------------------------------------------------------------------+ | |rcu_init_geometry | | | | | |根据实际运行时cpu核数(nr_cpu_ids)初始化树形RCU的几何结构, | | |具体就是:树的每层有多少节点(num_rcu_lvl[]数组。最后一层是rcu_data), | | | 树有多少非叶子节点,也就是rcu_node数量(rcu_num_nodes)。 | +---+ 树非叶子节点的层数,也就是rcu_node层数(rcu_num_lvls), | | |以典型编译配置的12核cpu为例, | | | num_rcu_lvl[0]=1,num_rcu_lvl[1]=12,rcu_num_nodes=1,rcu_num_lvls=1。 | | |以典型编译配置的48核cpu为例, | | | num_rcu_lvl[0]=1,num_rcu_lvl[1]=3,num_rcu_lvl[2]=48,rcu_num_nodes=4,rcu_num_lvls=2。| | |另外设置了jiffies_till_first_fqs,jiffies_till_next_fqs这两个值。 | | +------------------------------------------------------------------------------------------+ | | +-----------------------------------------------------------------------------+ | |调用rcu_init_one初始化以下两个rsp。 | | |初始化rcu_sched_state,用于经典RCU | +---|初始化rcu_bh_state,用于经典RCU后缀_bh那组api | | |初始化过程包括rsp、rnp(中间节点)和rdp(cpu叶子节点)的初始化 | | |对rdp的初始化由函数rcu_boot_init_percpu_data完成。 | | |rdp中nocb相关成员nocb_tail和nocb_wq由函数rcu_boot_init_nocb_percpu_data完成。| | +-----------------------------------------------------------------------------+ | | +--------------------------------------------------+ +---+__rcu_init_preempt | | |如果开启了可抢占式RCU,内部封装rcu_init_on,否则空| | |只对可抢占RCU有意义,只是初始化了rcu_preempt_state| | +--------------------------------------------------+ | | +--------------------------------+ +---+ 注册RCU_SOFTIRQ软中断 | | |处理函数为 rcu_process_callbacks| | +--------------------------------+ | | +---------------------------------------------------------------------------------------+ | |注册CPU热拔插事件处理函数并对每个CPU做上线操作,上线操作会调用三个函数 | | | rcu_prepare_cpu | | | 对该CPU在每个rsp上调用rcu_init_percpu_data, | | | 这个操作会将该cpu对应的rdp的grpmask向上汇总到父节点的qsmaskinit,逐层进行。 | +---| rcu_prepare_kthreads | | | 调用rcu_spawn_one_boost_kthread, | | | 这个操作给rdp的父节点rnp创建一个RCU-boost内核线程,用于可抢占RCU,这里不关注。 | | | rcu_spawn_all_nocb_kthreads | | | 对该CPU在每个rsp上调用rcu_spawn_one_nocb_kthread, | | | 这个操作给nocb的CPU每一个rsp创建一个rcuo内核线程(使用函数rcu_is_nocb_cpu)判断。 | | | 内核线程执行函数为rcu_nocb_kthread,线程task_struct结构指针赋值给nocb_kthread成员。| | +---------------------------------------------------------------------------------------+ | | v 返回
rcu_init_nohz的逻辑比较简单,根据编译配置和启动配置将需要做nocb的 CPU号写入位图rcu_nocb_mask中,然后对每一个nocb CPU调用init_nocb_callback_list(其实就是设置rdp->nxttail[RCU_NEXT_TAIL] = NULL,这个值就是检查rdp是否启用nocb的标识)。
内核线程初始化代码如下(暂时不深究early_initcall如何生效):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static int __init rcu_spawn_gp_kthread (void ) unsigned long flags; struct rcu_node *rnp ; struct rcu_state *rsp ; struct task_struct *t ; rcu_scheduler_fully_active = 1 ; for_each_rcu_flavor(rsp) { t = kthread_run(rcu_gp_kthread, rsp, rsp->name); BUG_ON(IS_ERR(t)); rnp = rcu_get_root(rsp); raw_spin_lock_irqsave(&rnp->lock, flags); rsp->gp_kthread = t; raw_spin_unlock_irqrestore(&rnp->lock, flags); } rcu_spawn_nocb_kthreads(); rcu_spawn_boost_kthreads(); return 0 ; } early_initcall(rcu_spawn_gp_kthread);
内核线程可以参考Linux kernel thread 内核线程 。
函数解释
rcu_cbs_completed
如果是rnp是根节点,并且gpnum等于completed(也就是当前gp已经结束了),那么返回completed + 1(因为下个gp结束completed将顺序递增1)。
如果上一条没满足,则返回completed + 2(这个预估是比较宽松的,实际可能只需要增1,但是在不向上检查时无法确定)。
rcu_start_future_gp
调用rcu_cbs_completed取得预估的序号c。
如果c在need_future_gp已经有标记,则返回c。
如果当前rnp的gpnum不等于completed,或者不等于rsp的completed。说明当前有gp在运行中。将c标记在need_future_gp中,返回c。
重新从根节点取rcu_cbs_completed返回值c。
如果c小于nxtcompleted数组中成员值,则修改为c(因为根节点的c小于等于中间节点的)。
如果c在need_future_gp已经有标记,则返回c。
将c标记在need_future_gp中。
调用rcu_start_gp_advanced设置开启新gp(运行到这里,说明有未完成的callback,并且有新标记需要完成的gp号。但是还是很绕啊,没懂……)。
rcu_start_gp_advanced
如果RCU内核线程没启动或者cpu_needs_another_gp返回假,则直接返回。
rsp->gp_flags赋值为RCU_GP_FLAG_INIT,这个值用于告诉内核线程需要开始新的gp序号。irq_work_queue(&rsp->wakeup_work);唤醒内核线程,具体唤醒流程先不关注了,之前由init_irq_work(&rsp->wakeup_work, rsp_wakeup);初始化过。
cpu_needs_another_gprsp->gp_flags赋值为RCU_GP_FLAG_INIT,用以告诉内核线程开始一个新的gp。具体判定顺序逻辑为:
如果当前gp未结束,返回假。
如果rcu_nocb_needs_gp返回真(依靠rsp中根节点rnp的need_future_gp中completed + 1在里面是否为真来判断,只是建议。这就可以判定存在nocb的callback吗?),返回真。
如果这是一个nocb CPU(通过RCU_NEXT_TAIL判定),返回假。
如果有刚刚注册的callback(通过RCU_NEXT_READY_TAIL判定),返回真。
如果nxtlist的中间两段有callback,并且预分配的nxtcompleted大于已经完成的completed,返回真。
如果以上都不满足,返回假。
rcu_accelerate_cbsrcu_cbs_completed取值并比较),并更新nxtcompleted数组。如果有合并和更新,还会调用rcu_start_future_gp。感觉是一个可有可无的函数,幂等。
rcu_advance_cbsrcu_accelerate_cbs将子链表尽量推进。
__rcu_process_gp_end
首先判断rdp的completed是否等于rnp的completed(completed是从上向下推进的)。
如果相等,说明没有callback需要放到RCU_DONE_TAIL前。调用rcu_accelerate_cbs加速处理进度。
如果不等,调用rcu_advance_cbs推进callback已完成的子链表。
然后修改rdp的completed为rnp的completed(终于将completed推进到rdp了)。
如果rdp的gpnum小于completed,修改gpnum为completed,修改passed_quiesce为0。(这里是为了eqs情况下可能丢失的gp)
如果rdp的grpmask在rnp的qsmask中不存在,设置rdp的qs_pending为0。
rcu_process_gp_end__rcu_process_gp_end前检查了rdp和rnp的completed是否相等,如果相等或是为rnp上锁失败则直接返回。
rcu_start_gprcu_start_gp_advanced不同之处在于前面多执行一个rcu_advance_cbs。这么处理的原因可能是为了避免无限的递归,这部分逻辑太坑了。
check_for_new_grace_period包装了note_new_gpnum,note_new_gpnum包装了__note_new_gpnum
force_quiescent_statersp->gp_flags增加标识RCU_GP_FLAG_FQS。这样RCU内核线程就会看到该标记并调用rcu_gp_fqs。
dyntick_save_progress_counterrdp->dynticks_snap用于后续rcu_implicit_dynticks_qs的判断。当gp超时或rsp被标记RCU_GP_FLAG_FQS时在rcu_gp_fqs中被调用。
rcu_implicit_dynticks_qsforce_quiescent_state配合在rcu_gp_fqs中被调用。一个gp中,首次进入rcu_gp_fqs会调用dyntick_save_progress_counter进行判断,后续进入将会调用rcu_implicit_dynticks_qs。此函数逻辑如下:
如果当前CPU处于动态时钟的idle状态,或者rdp->dynticks->dynticks相比dyntick_save_progress_counter记录的rdp->dynticks_snap差值大于等于2(说明至少经历了一次动态时钟的idle状态)。返回真。
如果gp经历时间不足两个tick,返回假。
如果CPU处于offline状态,返回真。
如果运行到了这里,有可能CPU处于动态时钟状态,这时没有时钟中断,因此调用rcu_kick_nohz_cpu开启CPU的时钟中断。
CPU还有可能在内核态运行了很长时间而没有经历qs,因此调用resched_cpu让CPU执行调度。
force_qs_rnprcu_report_qs_rnp将rnp的qsmask更新并向上汇报。此函数唯一的调用位置是rcu_gp_fqs中。传入的函数指针就是dyntick_save_progress_counter或rcu_implicit_dynticks_qs。
rcu_gp_fqsRCU_GP_FLAG_FQS被设置,会调用此函数强制检查qs(也就是检查eqs并激活CPU的时钟中断或强制调度)。
__rcu_pending
如果rds成员qs_pending为1,同时passed_quiesce也为1,这说明需要上报qs事件。返回1。
如果cpu_has_callbacks_ready_to_invoke返回1(实际就是rdp回调列表nxtlist在RCU_DONE_TAIL前存在元素),说明有回调可以被执行了。返回1。
如果cpu_needs_another_gp返回1。
如果rnp的completed不等于rdp的completed,说明有gp已经完成了,而且当前rdp还没有感知,因为completed是从上到下传递的,这时需要软中断将gp的完成事件传递到rdp上并进行相应处理。
如果rnp的gpnum不等于rdp的gpnum,说明有新的gp开始了,而且当前rdp还没有感知,因为gpnum也是从上到下传递的,需要软中断中进行处理。
如果上面都不满足,说明没有事情可以做,返回0。
rcu_pending__rcu_pending的包装,里面遍历了所有类型的rsp,有一个返回真函数既返回真。
rcu_report_qs_rdprcu_report_qs_rnp向上汇报给rnp,用于通知rnp该CPU已经经历过qs了。这个函数的唯一调用点是软中断处理函数中的rcu_check_quiescent_state。
rcu_report_qs_rnprcu_report_qs_rsp。该函数有两个调用位置,一个是rcu_report_qs_rdp末尾,一个是force_qs_rnp做强制qs检查时。
rcu_report_qs_rsprcu_report_qs_rnp中。
rcu_check_quiescent_state
注册回调 以call_rcu为例,实现为__call_rcu,逻辑主要为将指定回调函数填充到rcu_head中,挂载到rdp的nxtlist末尾。
call_rcu 1 2 3 4 5 6 7 8 9 10 11 12 13 #define call_rcu call_rcu_sched void call_rcu_sched(struct rcu_head *head, void (*func)(struct rcu_head *rcu)) { __call_rcu(head, func, &rcu_sched_state, -1 , 0 ); } EXPORT_SYMBOL_GPL(call_rcu_sched);
__call_rcu 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 static void __call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu), struct rcu_state *rsp, int cpu, bool lazy) { unsigned long flags; struct rcu_data *rdp ; WARN_ON_ONCE((unsigned long )head & 0x3 ); debug_rcu_head_queue(head); head->func = func; head->next = NULL ; local_irq_save(flags); rdp = this_cpu_ptr(rsp->rda); if (unlikely(rdp->nxttail[RCU_NEXT_TAIL] == NULL ) || cpu != -1 ) { int offline; if (cpu != -1 ) rdp = per_cpu_ptr(rsp->rda, cpu); offline = !__call_rcu_nocb(rdp, head, lazy); WARN_ON_ONCE(offline); local_irq_restore(flags); return ; } ACCESS_ONCE(rdp->qlen)++; if (lazy) rdp->qlen_lazy++; else rcu_idle_count_callbacks_posted(); smp_mb(); *rdp->nxttail[RCU_NEXT_TAIL] = head; rdp->nxttail[RCU_NEXT_TAIL] = &head->next; if (__is_kfree_rcu_offset((unsigned long )func)) trace_rcu_kfree_callback(rsp->name, head, (unsigned long )func, rdp->qlen_lazy, rdp->qlen); else trace_rcu_callback(rsp->name, head, rdp->qlen_lazy, rdp->qlen); __call_rcu_core(rsp, rdp, head, flags); local_irq_restore(flags); }
__call_rcu_core 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 static void invoke_rcu_core (void ) if (cpu_online(smp_processor_id())) raise_softirq(RCU_SOFTIRQ); } static void __call_rcu_core(struct rcu_state *rsp, struct rcu_data *rdp, struct rcu_head *head, unsigned long flags) { if (!rcu_is_watching() && cpu_online(smp_processor_id())) invoke_rcu_core(); if (irqs_disabled_flags(flags) || cpu_is_offline(smp_processor_id())) return ; if (unlikely(rdp->qlen > rdp->qlen_last_fqs_check + qhimark)) { rcu_process_gp_end(rsp, rdp); check_for_new_grace_period(rsp, rdp); if (!rcu_gp_in_progress(rsp)) { struct rcu_node *rnp_root = rcu_get_root (rsp ); raw_spin_lock(&rnp_root->lock); rcu_start_gp(rsp); raw_spin_unlock(&rnp_root->lock); } else { rdp->blimit = LONG_MAX; if (rsp->n_force_qs == rdp->n_force_qs_snap && *rdp->nxttail[RCU_DONE_TAIL] != head) force_quiescent_state(rsp); rdp->n_force_qs_snap = rsp->n_force_qs; rdp->qlen_last_fqs_check = rdp->qlen; } } }
顺便说一下synchronize_rcu,这个函数其实就是调用__call_rcu,然后让当前进程调度走并等待一个struct completion,grace period完成后调用callback设置刚才的completion唤醒等待的进程,也就是说核心依然是__call_rcu和RCU中对grace period的处理。
检查回调 RCU对grace period的处理过程比较复杂,涉及中断、软中断及内核线程配合处理。
中断部分 RCU的激活检查由函数rcu_check_callbacks完成,在update_process_times中被调用,由每个CPU的本地定时器中断触发,可以参考timer定时器中硬件定时器初始化部分 。
主要功能就是判断是否处于qs(不同rsp判断qs的标准不同),如果处于qs就更新相应rsp中当前CPU的rdp,然后根据是否需要软中断做进一步处理选择是否激活软中断。
RCU中断流程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 +-------------------+ |rcu_check_callbacks| +--+----------------+ | | +-------------------------------------------------------------+ +---+ increment_cpu_stall_ticks | | |增加所有rsp下当前CPU的rdp成员ticks_this_gp,用于检测CPU长期占| | +-------------------------------------------------------------+ | | | +--------------------------------------------------------+ | |如果中断发生时位于用户态或处于CPU idle状态,调用两个函数| +---+ rcu_sched_qs | | | rcu_bh_qs | | +--------------------------------------------------------+ | | +--------------------------------------------------------+ +---+如果不处于用户态或CPU idle状态,同时也不在软中断中,调用| | | rcu_bh_qs | | +--------------------------------------------------------+ | | | | +--------------------------------------------------------+ +---+rcu_preempt_check_callbacks | | |可抢占RCU相关,在未配置CONFIG_TREE_PREEMPT_RCU时是空函数| | +--------------------------------------------------------+ | | | +-------------------------------------------------+ +---|如果rcu_pending为真(就是需要软中断干活了),调用| | |invoke_rcu_core(实际就是激活RCU_SOFTIRQ软中断) | | +-------------------------------------------------+ | v 返回
rcu_sched_qs逻辑很简单,只是标记rcu_sched_state对应的rdp成员passed_quiesce为1。因为该CPU不处于内核代码的上下文,因此一定不在rcu_read_lock开始的临界区中(因为临界区是关闭内核抢占的,不会发生内核抢占,进入用户态或idle状态就说明经历了调度),说明该CPU经过了静止状态。
rcu_bh_qs逻辑也是一样,标记rcu_bh_state对应的rdp成员passed_quiesce为1。因为该CPU不处于软中断上下文,因此一定不在rcu_read_lock_bh开始的临界区中,说明该CPU经过了静止状态。
软中断部分 RCU在每个CPU的主要处理部分在RCU_SOFTIRQ软中断中进行,函数为rcu_process_callbacks,这个函数只是遍历所有rsp并调用__rcu_process_callbacks。
rcu_process_callbacks 1 2 3 4 5 6 7 8 9 10 11 12 13 14 static void rcu_process_callbacks (struct softirq_action *unused) struct rcu_state *rsp ; if (cpu_is_offline(smp_processor_id())) return ; trace_rcu_utilization("Start RCU core" ); for_each_rcu_flavor(rsp) __rcu_process_callbacks(rsp); trace_rcu_utilization("End RCU core" ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 +-----------------------+ |__rcu_process_callbacks| +-----------------------+ | | +-------------------------------------------------------------------------+ | |rcu_process_gp_end | +---+这里对已经完成的callback在nxtlist链表上进行推进,放入已经完成gp的子链表。| | |并向completed从rnp向下传递到rdp。 | | +-------------------------------------------------------------------------+ | | +-------------------------+ +---+rcu_check_quiescent_state| | +--+----------------------+ | | | | +-----------------------------------------------------------------------+ | | |check_for_new_grace_period | | | | | | +---+检查是否开始有新的gp,如果有则将gpnum从rnp向下传递到rdp, | | | |并更新rdp的qs_pending和passed_quiesce。 | | | | | | | |这个函数返回真的话,说明有新的gp,那么rcu_check_quiescent_state直接返回| | | +-----------------------------------------------------------------------+ | | | | +--------------------------------------------------------------+ | +---+如果rdp的qs_pending为假,说明当前gp不需要这个CPU的qs,直接返回| | | +--------------------------------------------------------------+ | | | | +------------------------------------------------------------------------+ | +---+如果rdp的passed_quiesce为假,说明当前gp在这个CPU上还没有经历qs,直接返回| | | +------------------------------------------------------------------------+ | | | | +------------------------------------------------------+ | | |rcu_report_qs_rdp | | +---+将qs完成情况向上汇报,如果最后根节点rnp的qsmask为0 了,| | | |就可以唤醒内核线程做gp结束的处理工作了。 | | | +------------------------------------------------------+ |<-----+ | | +-----------------------------------+ +---+如果cpu_needs_another_gp返回真,调用| | |rcu_start_gp开始一个新gp | | +-----------------------------------+ | | +-----------------------------------------------------------------------------------+ +---+如果cpu_hash_callbacks_ready_to_invoke返回真(判断nxtlist上是否有完成gp的callback)| | |调用 invode_rcu_callbacks | | +--+--------------------------------------------------------------------------------+ | | | | +-------------------------------------------------------+ | +---+如果启用了rcu boost,则调用invoke_rcu_callbacks_kthread| | | +-------------------------------------------------------+ | | | | +--------------------------------------------------------------------------+ | | |否则调用 rcu_do_batch | | | | | | | |这里不细说了,大概就是根据rdp中blimit的值批量运行一部分callback,然后判断 | | +---+如果当前是idle进程上下文或者运行运行在单独的内核线程中,并且没有调度的需求| | | |那么还可以接续运行更多的callback。否则会停止运行callback。 | | | |最后如果有剩余的callback没运行,再放回nxtlist头部等待下次rcu_do_batch, | | | |还更新了一些rdp中的成员值,细节。 | | | +--------------------------------------------------------------------------+ |<-----+ | v 软中断部分完成
内核线程部分 每个rsp有一个内核线程负责grace pierod的开始和结束。为什么创建一个线程独立负责这部分,我只能猜测是为了避免grace period开始时并发操作rsp时锁的spin,由一个独立线程负责可以避免冲突,软中断中只要直接从内存读取rsp相关成员就可以了。
rcu_gp_kthread内部是一个不会退出的循环:
rcu_gp_kthread 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 +--------------+ |rcu_gp_kthread| +------+-------+ | | +--->| | | | | +------------------------------------------------+ | +---+循环等待`rsp->gp_flags & RCU_GP_FLAG_INIT`为真,| | | |这时说明应该为该rsp开启一个新的grace period。 | | | +------------------------------------------------+ | | | | +--------------------------------------------------------------+ | +---| rcu_gp_init 开启一个新的grace period | | | |开启与新的grace period,由内核线程唯一负责,该函数的唯一调用点| | | +--------------------------------------------------------------+ | | | | | | +----------------------------+ | | +---+rsp->gp_flags置0 ,清理标记。| | | | +----------------------------+ | | | | | | +-------------------------------------------------+ | | +---+rsp->gpnum ++,记录当前新开始的grace period序号。| | | | +-------------------------------------------------+ | | | | | | +-----------------------------+ | | +---+遍历所有的rnp,进行以下操作:| | | | +--+--------------------------+ | | | | | | | | +----------------------------------------------+ | | | +----|rnp->qsmask设置为rnp->qsmaskinit, | | | | | | qsmask用于标记下属rnp或rdp静止状态的完成情况| | | | | | 经历过静止状态的节点会清除相应bit位。 | | | | | +----------------------------------------------+ | | | | | | | | +--------------------------------------------------------------------------+ | | | +----+rnp->completed设置为rsp->completed, | | | | | | 这个操作有点像冗余操作,因为在这个线程调用`rcu_gp_cleanup`时会更新该值。| | | | | +--------------------------------------------------------------------------+ | | | | | | | | +-----------------------------------------+ | | | +----+rnp->gpnum设置为rsp->gpnum | | | | | | 可以看到gpnum是由rsp向下传递到所有rnp的| | | | | +-----------------------------------------+ | | | | | | | | +---------------------------------------------+ | | | +----+如果操作的rnp是当前CPU对应的rdp的父节点,调用| | | | | |rcu_start_gp_per_cpu (该函数的唯一调用点) | | | | | +--+------------------------------------------+ | | | | | | | | | | +--------------------+ | | | | | |__rcu_process_gp_end| | | | | | +--------------------+ | | | | | 这里作用是加速callback子表合并,和推进已经完成gp的callback到完成子表。 | | | | | 参考函数解释节。 | | | | | | | | | | +----------------+ | | | | +---+__note_new_gpnum| | | | | | +----------------+ | | | | | 这里将新的gpnum向下推进到rdp上。并更新passed_quiesce和qs_pending。 | | | | | | | | |<------+ | | | | | | | | +--------------------------+ | | | +----+rcu_preempt_boost_start_gp| | | | | +--------------------------+ | | | | boost相关,不关注 | | | | | | |<-----+ | | | | |<----+ | | | | | | +---------------------------------------------------------------------------+ | | |循环等待根节点`rnp->qsmask`为0 , | | +---+这时说明所有的CPU都经历过静止状态,可以结束当前grace period。 | | | |在超时或rsp中RCU_GP_FLAG_FQS被设置时,会调用rcu_gp_fqs强制检查qs(或eqs),| | | |这里也可能清除符合条件的CPU的掩码位并逐级向上汇报。参考函数解释节。 | | | +---------------------------------------------------------------------------+ | | | | | | +---------------------------------------+ | +---+`rcu_gp_cleanup` 结束当前grace period。| | | +-+-------------------------------------+ | | | | | | +-----------------------------+ | | +---+遍历所有的rnp,进行以下操作:| | | | +--+--------------------------+ | | | | | | | | +------------------------------+ | | | +----+rnp->completed设置为rsp->gpnum| | | | | +------------------------------+ | | | | | | | | +-----------------------------------------------------------------------+ | | | +----+如果操作的rnp是当前CPU对应的rdp的父节点,调用 | | | | | |__rcu_process_gp_end,用于推进当前CPU上已经完成gp的callback等待被执行。| | | | | +-----------------------------------------------------------------------+ | | | | | | | | +-----------------------------------------------------------+ | | | | |rcu_future_gp_cleanup | | | | +----+清除rnp成员need_future_gp中刚刚完成的gp序号标记, | | | | | |并返回下一个gp序号标记是否需要开启。 | | | | | |这里会调用rcu_nocb_gp_cleanup唤醒等待该gp完成的nocb内核线程| | | | | +-----------------------------------------------------------+ | | | | | | |<-----+ | | | | | | +------------------------------------------------+ | | +---+rcu_nocb_gp_set,传入根节点rnp。nocb相关先不关注|| | | | +------------------------------------------------+ | | | | | | +----------------------------------------------+ | | +---+rsp->completed设置为rsp->gpnum,当前gp正式完成| | | | +----------------------------------------------+ | | | | | | +---------------------------------------------------------+ | | +---+rsp->fqs_state = RCU_GP_IDLE,实际上rsp中该成员并没有用到| | | | +---------------------------------------------------------+ | | | | | | +--------------------------------------------+ | | | |rcu_advance_cbs | | | +---+推进当前CPU的rdp上的callback链表, | | | | |这样下一步操作可以减少误判以避免无谓开始新gp| | | | +--------------------------------------------+ | | | | | | +------------------------------------------------+ | | | |如果cpu_needs_another_gp返回真, | | | +---+ rsp->gp_flags设置为RCU_GP_FLAG_INIT, | | | | | 这样该线程再次循环时就会开启新的grace period。| | | | +------------------------------------------------+ | | | | |<----+ | | | | +<---+ 开始下一个循环