Linux kernel 链路层帧接收
Linux kernel接收链路层帧时涉及中断部分、软中断部分,具体数据接收过程根据网卡驱动不同有传统的中断方式接收与NAPI方式接收,本文会分析两种方式的具体接收过程及两者的不同之处。
本文内容参考内核版本 3.10.0-862.el7.x86_64
ps:用词上不区分帧与数据包。
数据结构
softnet_data
网络数据包接收中一个重要变量是per-cpu变量的softnet_data,使用中简称为sd,其中统一了非napi驱动和napi驱动的处理逻辑。几个后文涉及的成员如下:
- input_pkt_queue
非napi设备ISR收包时将skb放入该队列,等待软中断处理。 - backlog
为了统一两种处理方式,为所有非napi设备设计了一个napi_struct结构,与每个napi设备都有一个napi_struct结构共同在软中断的处理框架中生效。 - process_queue
非napi设备在软中断中处理input_pkt_queue中数据包时,先先将skb链表转移挂载到这里。目的是尽快释放input_pkt_queue上的锁,这样同cpu上的ISR及其他cpu上的rps逻辑可以使用input_pkt_queue。 - poll_list
链表挂载了所有在软中断中需要进一步处理的napi设备的napi_struct结构,同时非napi设备共用的backlog成员在需要处理数据包时也将挂载于此。
1 | /* |
napi_struct
设备收包使用的结构体,这里看几个成员:
- poll_list
链表结构,用于挂载到sd->poll_list上。 - poll
收包处理函数指针,软中断中调用以进行收包及数据包处理。 - weight
权重,每次最多处理数据包数。
1 | /* |
packet_type
数据包完成链路层处理后,需要提交给协议栈上层继续处理,每个packet_type结构就是数据包的一个可能去向。
- type
ETH_P_ALL或具体三层协议号,标记该packet_type收取什么类型的数据包,需要网络字节序。 - dev
如果该packet_type只收取特定设备的数据包,则以该成员标识。 - func
数据包后续真正的处理函数。比如IP协议的处理函数为ip_rcv。 - id_match
看起来好像用来判断一个发出的数据包是否应该被该packet_type收取。因为这个函数指针使用的方式与af_packet_priv == skb->sk在一起且逻辑一致。 - list
链表使用。
1 | struct packet_type { |
packet_type结构体注册生效涉及两个全局变量和两个net_device结构内成员
ptype_all
一个链表结构,注册了收取所有设备所有数据包的packet_type。ptype_base
一个哈希表结构,每个槽位是一个链表,注册了收取所有设备特定协议数据包的packet_type。哈希结构用于通过协议号快速匹配。dev->extended->ptype_all
一个链表结构,注册了只收取该设备所有数据包的packet_type。dev->extended->ptype_specific
一个链表结构,注册了只收取该设备特定协议数据包的packet_type。
1 | ```void dev_add_pack(struct packet_type *pt) |
中断方式接收
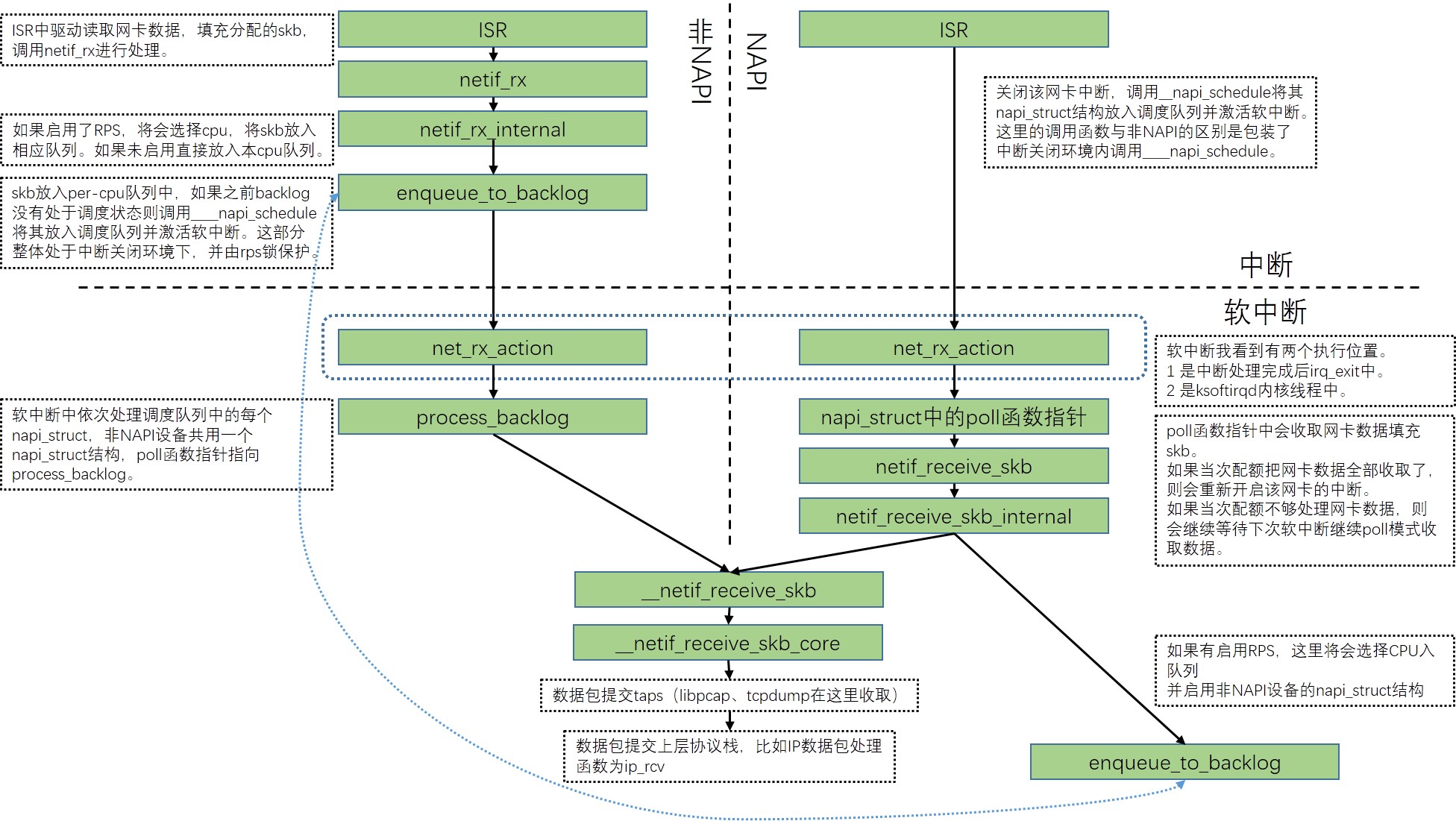
这种方式的主要特征为,中断服务例程(ISR)中收取网卡数据填充sk_buff(后续称为skb)结构并放入内核内存,软中断中继续完成skb的处理并逐层递交上层协议栈处理。软中断处理过程中网卡中断始终开启。
中断方式接收数据是传统的Linux收包方式,这里参考3com的3c59x驱动介绍,文件为drivers/net/ethernet/3com/3c59x.c。
中断部分
- ISR为函数
vortex_interrupt,这里会循环处理最多32个数据包,当有数据包需要接收时调用函数vortex_rx。 vortex_rx中会配分一个skb(这个skb将会贯穿整个协议栈的处理过程),从设备读取数据写入skb(这里会区分dma方式与cpu读取方式),数据读取完毕后调用函数eth_type_trans确定三层协议并写入skb->protocol,对skb调用函数netif_rx(这是中断方式驱动接收数据进入内核处理代码的统一入口)。netif_rx是中断方式驱动程序接收数据进入内核处理的统一入口,是函数netif_rx_internal的一个包装。这里根据编译配置和运行配置区分为是否启用RPS(一种软件方式模拟多队列网卡RSS的技术,通过将不同flow的数据包分布到不同cpu进行后续处理的方式增强全局处理能力),如果启用了RPS将会选择一个cpu调用enqueue_to_backlog,如果未启用RPS将会对当前cpu调用enqueue_to_backlog。enqueue_to_backlog前后通过get_cpu和put_cpu确保内部处于抢占关闭状态(个人理解为,这个函数可能在中断上下文之外的环境中被调用,put_cpu是preempt_enable的宏定义,在内核可抢占配置下preempt_enable内部隐含了可能的抢占调度,这可以使数据包入队列后尽快启动软中断处理过程,在可能的情况下尽快处理数据包。可抢占调度的前提为需要调度标记处于开启状态、preempt_count为0、中断处于关闭状态)enqueue_to_backlog- 首先关闭了中断(这里很好理解,因为这个函数后续操作的数据结构可能被其他的ISR访问,为了避免冲突必须关闭中断。因为关闭中断的情况下是不会发生抢占调度的,因此印证了前文中的put_cpu是为了尽快启动软中断这一目的。)
- 如果配置了RPS,将会上spinlock对临界区进行保护,避免其他cpu的并发冲突。如果没有配置RPS则没有spinlock操作,因为操作临界区资源是per-cpu变量,关闭中断的情况下当前cpu不会有其他代码操作临界区资源。
- 如果per-cpu类型softnet_data变量sd中input_pkt_queue队列空,则将非napi设备共用的napi_struct结构sd->backlog的status设置为
NAPI_STATE_SCHED然后挂载到sd->poll_list上并将当前cpu的软中断NET_RX_SOFTIRQ置于激活状态,这样当后续处理中软中断可以执行时将继续处理数据包。然后将skb放入sd->input_pkt_queue末尾。如果input_pkt_queue不为空,说明软中断NET_RX_SOFTIRQ之前已经激活过并等待运行,不需要再额外激活,而且backlog已经挂载到poll_list,直接将skb放入input_pkt_queue末尾既可。 - 开启之前关闭的中断。
这里运行结束后,收包中断的上半部已经完成,input_pkt_queue中的skb后续将在下半部软中断中继续处理。
软中断部分
net_rx_action是NET_RX_SOFTIRQ软中断处理函数,这个函数逻辑如下:
- 将
sd->poll_list上挂载的napi_struct全部取下保存到局部变量list中。由于这步操作的是per-cpu变量,而且可能与ISR操作冲突,因此需要处于中断关闭环境。 - 依次对
list每个napi_struct结构调用函数napi_poll,参数传入局部变量repoll地址,用于当数据包未全部处理时标记后续需要继续处理。直到全部处理完毕或处理超过300个数据包或执行超过2个时钟滴答(如果HZ为1000,也就是2毫秒)。- 将
napi_struct结构从链表中摘除。如果有配置netpoll且设备启用了netpoll的话,还需要持续尝试当前cpu获取napi->poll_owner,以避免与其他cpu上netpoll的冲突。 - 检查status是否为NAPI_STATE_SCHED而后调用
napi_struct结构的poll函数指针完成对数据的操作。前文说过,非napi设备共用sd->backlog这个napi_struct,napi设备每个驱动有自己的napi_struct,生效位置就是这里。 - 如果poll返回已经处理的数据包数小于提供的配额,说明已经没有数据包需要处理,不需要后续挂载到repoll了,因此直接返回。
- 判断是否disable了,并做相应处理。
- 判断网卡驱动是否已经将该
napi_struct重新挂载到某链表上(有些驱动会自主调用napi_schedule,这是不应该的),如果已经挂载则printk警告信息,后续不做其他操作。 - 如果进行到了最后说明poll函数指针运行消耗了所有的配额,可能仍有数据包未处理完成,因此这里将其重新挂载到repoll链表上等待后续再次激活。
- 将
- 将
list、repoll、sd->poll_list上挂载的napi_struct依次重新挂载到sd->poll_list上,这个顺序表明下次软中断中需要处理的网络设备顺序分别是本次未来得及处理的、本次未处理完全的、新增的。如果sd->poll_list非空将会标记NET_RX_SOFTIRQ为激活等待再次执行。这部分操作同样需要处于中断关闭环境。
process_backlog是sd->backlog->poll函数指针指向的函数,在net_dev_init中初始化。这里有一些对配额的调整逻辑不做赘述,主要逻辑为:
- 将
sd->input_pkt_queue中链接的数据包转移挂载到sd->process_queue上。这一步的目的应该是在rps环境下可以尽快释放input_pkt_queue的锁,这样其他cpu才可能根据rps将数据包放入该队列。 - 循环处理
process_queue上的每个skb,直到队列为空或处理数据包数达到配额。处理函数为__netif_receive_skb。 - 返回处理的数据包数。
__netif_receive_skb是函数__netif_receive_skb_core的一个包装,__netif_receive_skb_core中完成了对skb真正的处理及提交上层协议栈。
- 保存
skb->dev到局部变量orig,因为后续这个dev可能发生变化。保存收包设备索引。如果是vlan包,脱掉vlan头。 - 遍历全局变量链表
ptype_all,对链接的每个packet_type结构调用函数deliver_skb
这一步与下一步一同构成了将skb提交到taps嗅探设备,比如libpcap使用的PF_PACKET。
ps:skb成员pfmemalloc标记会引发跳过对ptype_all的处理。 - 遍历
skb->dev->extended->ptype_all,对链接的每个packet_type结构调用函数deliver_skb
这一步与上一步一同构成了将skb提交到taps嗅探设备,比如libpcap使用的PF_PACKET。区别在于这里的是只嗅探特定net_device的。
s:skb成员pfmemalloc标记同样会引发跳过此步骤。 - 有一段对
skb->dev->rx_handler的处理,好像是与虚拟网络设备相关,这部分先跳过。 - 遍历
ptype_base上特定的哈希槽,对匹配协议号的packet_type结构调用函数deliver_skb
这一步与下一步一同构成了将skb提交到上层协议栈。这一步有一个判断条件与之前的rx_handler有关,暂时不关心。 - 遍历
orig_dev->extended->ptype_specific,对匹配协议号的packet_type结构调用函数deliver_skb
这一步与上一步一同构成了将skb提交到上层协议栈。区别在于这里的是只对特定net_device有效的协议栈。 - 如果到这里skb成员dev发生了变更,遍历
skb->dev->extended->ptype_specific,对匹配协议号的packet_type结构调用函数deliver_skb
上文的deliver_skb内部实际增加了skb的引用计数,然后调用packet_type成员func函数指针将skb提交到上层协议栈,对skb的释放操作将由func指向的函数具体负责。另外对func的调用每次都是延迟处理,最后一次调用甚至抛开了deliver_skb直接调用func,个人理解为由于最后__netif_receive_skb_core不再持有skb了,因此引用计数可以直接传递给最后一次调用的func,这样也就省去了一次kfree_skb的函数调用。这里贴一下IP协议的packet_type,可以看到IP协议数据包的处理函数是ip_rcv。到这里链路层部分已经完成了,但是软中断工作并没有完成,软中断中将继续进行上层协议栈的处理。
1 | static struct packet_type ip_packet_type __read_mostly = { |
NAPI方式接收
NAPI既New API,这种方式的主要特征为,ISR中只将需要接收数据的网卡放入一个特定的待接收列表中,并标记需要在软中断中接收网卡数据,所有的数据接收及协议栈上的逐层处理都在软中断中完成。ISR中会关闭网卡中断,直到软中断处理了该网卡所有数据后才会将该网卡中断开启。
NAPI方式接收数据是较新一些的Linux收包方式,这里参考intel的e100驱动介绍,文件为drivers/net/ethernet/intel/e100.c。
中断部分
ISR为函数e100_intr,逻辑如下:
- 检查该网卡是否可以调度由当前cpu接收数据包,如果不可以将不会进行后续步骤。(可以调度的话,会将
napi_struct的status设置为NAPIF_STATE_SCHED。) - 关闭该网卡中断。
- 将该网卡的
napi_struct结构挂载到per-cpu变量sd->poll_list上,将当前cpu软中断NET_RX_SOFTIRQ标记为激活等待执行。
到这里中断部分就处理完成了,而且该网卡的中断后续将处于关闭状态。
软中断部分
软中断入口的开始部分与非NAPI方式完全相同,只是napi_struct结构的poll函数指针不同,e100驱动的poll函数指针指向为函数e100_poll
收包函数e100_rx_clean内部在填充skb后调用的函数栈为netif_receive_skb->netif_receive_skb_internal->__netif_receive_skb,这里就是上文描述过的了。
最后处理的工作量如果小于配额,说明已经全部处理完,这时调用napi_complete处理该结构,并重新开启该网卡中断。
1 | static int e100_poll(struct napi_struct *napi, int budget) |
对比
NAPI方式在数据包量较大时可以降低中断数量。设想一个场景,有大量小包到来,如果是非NAPI设备将会有大量的中断产生,中断是可以打断软中断执行的,cpu时间大量占用在中断处理上,此时软中断中数据包真正的处理无法进行。NAPI在大量数据包到来时使用poll轮询的方式收取数据包使cpu可以更有效的处理数据包。
但是可以看到3c59x驱动中每次中断也设定了可以收取多个数据包,在一定程度上也可以减少中断的数量。